
DB(6) 비정규화 데이터 베이스
이전 정규화 데이터 베이스에 이어 비정규화 데이터베이스(denormalized database)도 정리해보자
0. 목차
- 역정규화란
- 비정규화란
1. 역정규화란
굉장히 많은곳에서 역정규화와 비정규화를 같은 의미로 설명하곤한다. 하지만 이들은 엄현히 다르다
이들을 먼저 비교해보자.
wiki인용
역정규화란
이전 정규화 데이터베이스에서 성능을 개선하기 위해 사용되는 전략.
컴퓨팅에서 역정규화는 일부 쓰기 성능 손실을 감수한다.
데이터를 묶거나 데이터의 복제 사본을 추가하여 데이터베이스 (읽기) 성능을 개선하려고 시도하는 과정
요약 역정규화는 정규화된 테이블을 (비정규화) 상태로 만들기위한 방법중 하나
비정규화 상태로 만드는 역정규화 프로세스는
데이터베이스의 완벽한 구조설계를 포기__하고 데이터의 __무결성을 떨어뜨리는 대신 관계형 데이터 베이스의 읽기 성능을 향상 시키는 방법이다.
조인은 굉장히 시간이 많이드는 작업이라 말한적 있다.
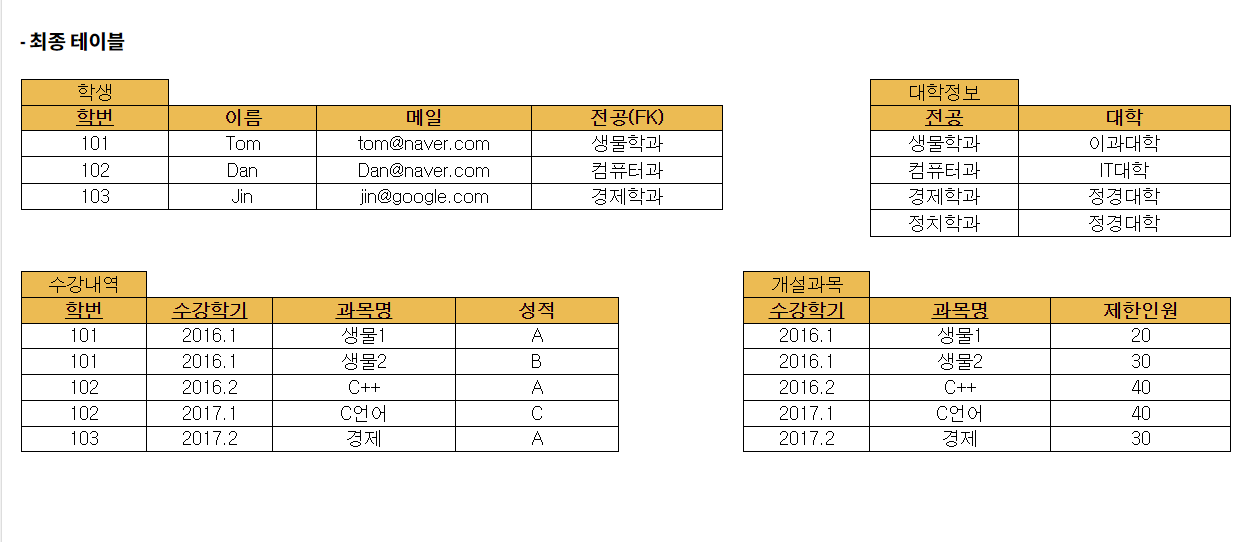
우리가 이전 포스팅에서 잘 분리하였던 위의 예시에서 [Tom의 성적과 그가 수강한 강의의 제한 인원을 알고 싶다면] 정보를 알고 싶다면 위같이 정규화된 테이블에선 학생 테이블에서 {학번, 이름, 전공}을 확인하고 수강 테이블에서 {과목명과, 성적}를 확인하고 개설과목 테이블에서 {제한인원}을 확인해야한다.
지금이야 테이블을 한눈에 볼수 있어 테이블을 옮겨다니며 하나씩 찾아가지만, 컴퓨터는 위 테이블들을 join해가며 데이터 값을 찾아간다.
만약 테이블의 개수가 엄청 많거나 테이블 안에 데이터가 많다면 JOIN시간이 엄청나게 늘어나 __데이터 읽기 효율성__이 굉장히 줄어들게 된다.
그래서 우리가 테이블을 정규화 과정 이전 상태로 돌린다면 Join할 필요가 없어져 데이터 읽기의 시간이 단출될수 있다.

다음 설명은 아래 비정규화로 내려가서 마저 하도록 하자.
2. 비정규화란
요약 정규화된 테이블(릴레이션)을 읽기성능 향상을 위해 다시 합치는 방법
위의 1번의 과정 {비정규화((역정규화))}을 할때 고려할 점이 생긴다.
- 무결성(데이터의 정확성)이 떨어진다.
- 데이터의 중복이 발생한다. (수정시 일부만 수정된다.)
- 읽기 속도는 빨라지지만 쓰기(삽입, 수정, 삭제) 속도는 느려진다.
- 이문제도 위의 중복된 데이터 사본떄문,
- 쓰기 작업보다 읽기가 중요할떄만 사용하도록하자
- 저장 공간효율이 떨어진다
- 유지보수가 어렵다.
- 테이블 자체가 커지고 복잡해져, 데이터를 쉽게 수정할수 없고 __확장성__이 현저히 떨어진다.
특별한 성능 이슈가 없을때만 비정규화를 진행하도록 하자! 또 이전에 비정규화 외에 다른 방법을 검토하는것도 팁!
- 뷰{View)를 사용해서 조인 문제를 해결할 수 있는지 검토
- 파티션(Partition)으로 데이터를 나눠서 해결할 수 있는지 검토
- 클러스터링(Clustering)이나 IOT(Index Oriented Table) 같은 특수 형태의 테이블을 사용해서 해결할 수 있는지 검토
- 인덱스를 조정하거나 힌트(Hint) 등으로 해결할 수 있는지 검토
- 그밖에 DBMS의 최신 기술을 적용해 해결할 수 있는지 검토
Comments