
GraphDB (1) 그래프 이론
오전 8시까지 밤샘 일을 하고 오니,,,, (블로그 쓰기가 너무 힘들어ㅓ,,,,,,,,)
오늘 한국어 그래프디비 구축 첫 회의가 있는날 이란걸 깨달았다..
아,,, 도착한지 3시간밖에 못잤는데,, 부랴부랴 들어가서 회의에 참석하고 간단 내용을 공유했다.
오늘은 간단히 소개와 기존에 제공되던 데이터들을 확인하는 자리였다.
그리고 이번주 미션은 그래프 이론에 대해 다시 알아오기, 학교다닐때 잠시 배우기도 했지만,, 아직 잘 모르는 ㅠ
그래서 오늘은 숙제겸 그래프이론을 다시금 공부해 보려한다,
목차
- 개요
- 그래프 관련 용어
- 그래프 종류
- 그래프 알고리즘
- 인접 리스트
- 인접 행렬
- 그래프 탐색
- 깊이 우선 탐색 DFS
- 너비 우선 탐색 BFS
- 코드로 보는 그래프 (python)
1. 개요
그래프 이론은 수학에서 객체 간의 짝을 이루는 관계를 모델링 하기위해 사용되는 수학 구조인 그래프에 대한 연구이다. 이 문맥에서 그래프는 꼭지점(vertex), 교점(node), 점(point) 으로 구성 되며 이것들을 변(엣지/EDGE/간선) 즉 선으로 연결한다. 그래프는 무향(무방향성) 일수 있는데 이는 각 변(엣지)로 연결되는 두개의 꼭지점 간에 구별이 없다는 의미이며, 한편 변은 한 꼭지점에서 다른 꼭지점에서 다른 꼭짓점 간에 방향이 있을수도 있다.
가장 일반적으로는 그래프는 순서쌍 G=(V, E)로 볼 수 있다. 여기에서 집합 V는 꼭지점 E는 간선을 의미한다. 혼동을 피하기 위해 이러한 형태의 그래프는 정확히 방향이 없는 단순한 그래프라고 기술할 수 있다.
2. 그래프 관련 용어
- 정점: vertex 위치 개념 (노드)
- 간선: edge 위치간의 관계, 즉 노드를 연결하는 선(link, branch라고도 부른다)
- 인접 정접: adjacent vertex, 간선에 의해 직접 연결된 정점
- 정접의 차수: degree, 무방향 그래프에서 하나의 정점에 인접한 정점의 수
- 무방향 그래프에 존재하는 정점의 모든 차수의 합 = 그래프 간선 수의 2배
- 진입 차수: 방향 그래프에서 외부에서 오는 간선의 수 (내차수)
- 진출 차수: 방향 그래프에서 외부로 향하는 간선의 수 (외차수)
- 경로 길이: path length, 경로를 구성하는 데 사용된 간선의 수
- 단순 경로: simple path, 경로 중에서 반복되는 정접이 없는 경우
- 사이클: 단순 경로의 시작 정점과 종료 정점이 동일한 경우
3. 그래프의 종류
- 그래프의 각 변에 방향을 추가하면, __유향 그래프__를 얻는다.
- 그래프의 각 변에 중복수를 추가하면 __다중 그래프__가 된다
- 그래프의 각 변에 +- 부호를 추가하면 __부호형 그래프__를 얻는다.
- 그래프의 각 꼭짓점에 색을 추가하면, 그래프 색칠을 얻는다.
그래프들은 또한 각종 구조들을 갖는다.
- 경로: 같은 꼭짓점을 거듭 거치치 않는 변들의 열
- 순환: 순환은 그래프 위의 스스로와 겹치지 않는 폐곡선(회로)라고 한다.
- 부분 그래프: 어떤 그래프의 꼭짓점과 변 가운데 일부로 이루어진 그래프이다.
- 연결 그래프:

- 위 그림에서 g1,g2,g3 는 모두 G의 부분 그래프이다.
- 마이너: 어떤 그래프의 변들을 축약시켜 얻은 그래프.
- 클릭: 모든 가능한 변이 존재하는 꼭짓점들의 부분 집합.
이러한 구조들을 통해 그래프들을 분류할 수 있다.
- 순환그래프
- 순환그래프는 정다각형의 그래프

- 완전그래프
- 완전 그래프는 서로 다른 두개의 꼭짓점이 반드시 하나의 변으로 연결된 그래프이다.
- 정규그래프
- 정규 그래프는 모든 꼭짓점이 동일한 수의 이웃을 가지는 그래프이다. 모든 꼭짓점이 모두 같은 __차수__를 가진다.

- 트리
- 나무 그래프
- 트리는 순환을 갖지 않는 연결 그래프이다.

- 완벽그래프
- 완벽 그래프는 그 색칠수가 클릭과 특별한 관계를 만족 시키는 그래프이다.
- 이분그래프
- 이분 그래프란 모든 꼭짓점을 빨강과 파랑으로 색칠하되, 모든 변이 빨강과 파랑 꼭짓점을 포함하도록 색칠할 수 있는 그래프
- 평면그래프
- 평면상에 그래프를 그렸을떄, 두변이 꼭짓점 이외에 만나지 않도록 그릴수 있는 그래프
- 삼차그래프 (정규 그래프)
- 모든 꼭짓점이 동일한 수의 이웃을 가지느 그래프, 즉 모든 꼭짓점이 같은 차수를 가진다. (페테르센 그래프, 완전 이분 그래프)
4. 그래프 알고리즘 (자료구조)
컴퓨터 시스템에서 그래프를 저장하는 방법은 여러가지가 있다. 이론적으로 그래프는 리스트와 행렬 구조중의 하나로 구별이 가능하다. 하지만 실제 적용에 있어서 최적의 자료구조는 이 두 구조의 조합된 형태를 띤다. 리스트 구조는 sparse graph에 적합하며, 적은 메모리 공간을 요구한다. 행렬 구조는 많은 양의 메모리를 필요로 하지만 더욱 빠른 접근을 제공한다.
4-1. 인접 리스트(Adjacency List)
인접 리스트로 그래프를 표현하는 것이 일반적인 방법
- 모든 정점(노드)를 인접 리스트에 저장한다. 즉, 각각의 정점에 인접한 정점들을 리스트로 표시한 것
- 배열 (혹은 해시테이블)과 배열의 각 인덱스마다 존재하는 또 다른 리스트 를 이용하여 인접 리스트를 표현한다.
- 정점의 번호만 알면 이 번호를 배열의 인덱스로 하여각 정점의 리스트에 쉽게 접근이 가능하다.
- 무방향 그래프에서 (a, b) 간선은 두 번 저장된다.
- 한 번은 a정점에 인접한 간선을 저장하고 다른 한 번은 b에 인접한 간선을 저장한다.
- 정점의 수: N 간선의 수: E인 무뱡향 그래프
- N개의 리스트, N개의 배열, 2E개의 노드가 필요
- 트리에선 특정 노드 하나 (루트 노드)에서 다른 모든 노드로 접근이 가능 -> Tree 클래스 불필요
- 그래프에선 특정 노드에서 다른 모든 노드로 접근이 가능한게 아님 -> Graph 클래스 필요
import java.util.LinkedList;
public class Graph {
int vertex;
LinkedList<Integer> list[];
public Graph(int vertex) {
this.vertex = vertex;
list = new LinkedList[vertex];
for (int i = 0; i <vertex ; i++) {
list[i] = new LinkedList<>();
}
}
public void addEdge(int source, int destination){
//add edge
list[source].addFirst(destination);
//add back edge ((for undirected)
list[destination].addFirst(source);
}
public void printGraph(){
for (int i = 0; i <vertex ; i++) {
if(list[i].size()>0) {
System.out.print("Vertex " + i + " is connected to: ");
for (int j = 0; j < list[i].size(); j++) {
System.out.print(list[i].get(j) + " ");
}
System.out.println();
}
}
}
public static void main(String[] args) {
Graph graph = new Graph(5);
graph.addEdge(0, 1);
graph.addEdge(0, 4);
graph.addEdge(1, 2);
graph.addEdge(1, 3);
graph.addEdge(1, 4);
graph.addEdge(2, 3);
graph.addEdge(3, 4);
graph.printGraph();
}
}
추가
인접 리스트는 인접 행렬보다도 구현하기가 훨씬 직관적이여서 더 자주 사용되곤 한다. 이름에서 알수 있듯 목록을 사용하여 노드 가장자리를 갖는 모든 노드를 나타낸다.
대부분의 인접리스트는 HashMaps 및 LinkedLists로 구현이 된다.
또한 인접 리스트는 방향 그래프에서 많이 선호된다. 방향성 그래프를 표현하는데 있어 더 직관적이기 떄문이다.
인접 리스트의 좋은점중 하나는 인접 행렬보다 객체 표현이 훨씬 쉽다는점이 있다.
인덱스가 아닌 노드를 객체로 사용하여 인접 목록으로 구현하는 것이 가능핟. 이러한 방법은 인접목록을 설명할때 훨신 명시적이고 선호되며, 프로젝트 내에서도 노드들을 객체로 관리할 가능성이 높기 떄문에 알아두면 유용하다=.
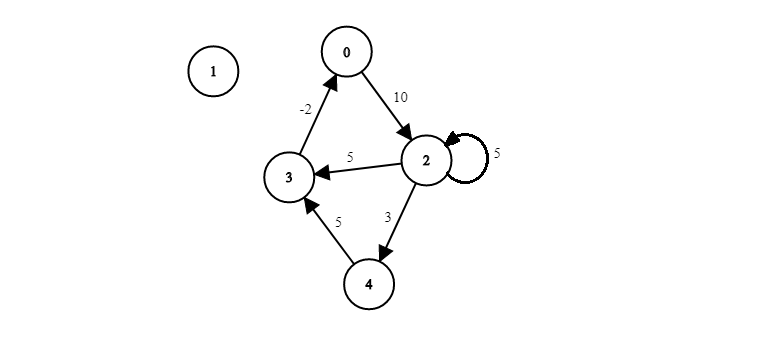
0: [2,10]
1: null
2: [2,5] -> [3,5] -> [4,3]
3: [0,-2]
4: [3,5]
인접 리스트 구현
이전 위 코드보다 복잡해 보일수도 있지만 자세히 보면 직관적인 코드 임을 알수 있다.
package adjacentlist;
public class Node {
int n;
String name;
Node(int n, String name) {
this.n = n;
this.name = name;
}
}
package adjacentlist;
import java.util.HashMap;
import java.util.LinkedList;
public class Graph {
// 각 노드맵은 모든 이웃 목록에 매핑이 된다.
private HashMap<Node, LinkedList<Node>> adjacencyMap;
private boolean directed;
public Graph(boolean directed) {
this.directed = directed;
adjacencyMap = new HashMap<>();
}
// add edge 메서드를 추가한다. 이번에는 특별히 helper 메서드를 사용해보도록 하자
// helper 메서드에서 중복 엣지 가능성을 체크한다.
// a와 b사이의 엣지를 추가하기 전에 먼저 기존에 엣지를 확인하고 있으면 기존 엣지를 삭제하고 추가한다.
public void addEdgeHelper(Node a, Node b) {
LinkedList<Node> tmp = adjacencyMap.get(a);
if (tmp != null) {
tmp.remove(b);
}
else tmp = new LinkedList<>();
tmp.add(b);
adjacencyMap.put(a,tmp);
}
public void addEdge(Node source, Node destination) {
// We make sure that every used node shows up in our .keySet()
if (!adjacencyMap.keySet().contains(source))
adjacencyMap.put(source, null);
if (!adjacencyMap.keySet().contains(destination))
adjacencyMap.put(destination, null);
addEdgeHelper(source, destination);
// If a graph is undirected, we want to add an edge from destination to source as well
if (!directed) {
addEdgeHelper(destination, source);
}
}
// 마지막으로 프린트 메서드와 엣지 여부 확인 메서드를 추가하자.
public void printEdges() {
for (Node node : adjacencyMap.keySet()) {
System.out.print("The " + node.name + " has an edge towards: ");
if (adjacencyMap.get(node) != null) {
for (Node neighbor : adjacencyMap.get(node)) {
System.out.print(neighbor.name + " ");
}
System.out.println();
}
else {
System.out.println("none");
}
}
}
public boolean hasEdge(Node source, Node destination) {
return adjacencyMap.containsKey(source) && adjacencyMap.get(source) != null && adjacencyMap.get(source).contains(destination);
}
}
4-2. 인접 행렬(Adjacency Matrix)
그래프 G=(V, E)를 n>=1 의 정점의 가진 그래프라고 할떄 그래프 G에 대한 인접행렬의 크기는 n*n이며 a[n, n] 크기의 2차원 배열로 표현된다. 이때 a[n, n] 에서 a[i, j] ∈ E(G) 라면 1 아니라면 0의 값을 가진다.
인접행렬의 표현방식에서 진입 차수와 진출차수는 a[i, j] ∈ E(G)의 경우에 i 행의 합을 구하면 진출 차수이고 i 열의 합을 구하면 진입 차수이다.
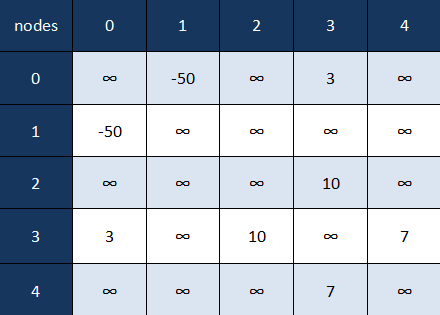
아래의 가중치 그래프의 경우 노드의 목록 대신 배열 목록이 필요하다. 배열은 엣지의 다른 쪽 끝에 있는 노드를 첫 번째 매개변수로 갖고, 연관된 가중치를 두번째 매개변수로 갖는다.
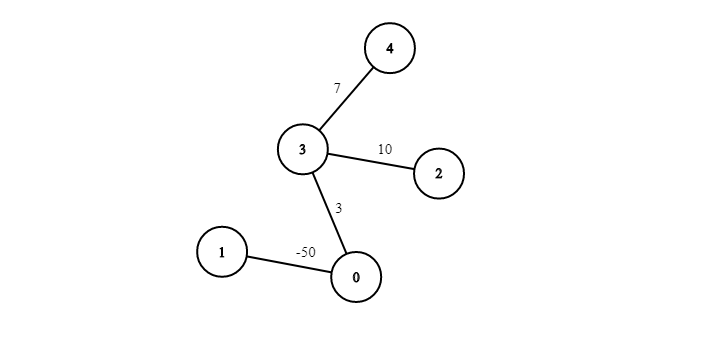
0: [1,-50] -> [3,3]
1: [0,-50]
2: [3, 10]
3: [0,3] -> [2,10] -> 4,7
4: [3,7]
public class GraphAjdacencyMatrix {
int vertex;
int matrix[][];
public GraphAjdacencyMatrix(int vertex) {
this.vertex = vertex;
matrix = new int[vertex][vertex];
}
public void addEdge(int source, int destination) {
//add edge
matrix[source][destination]=1;
//add bak edge for undirected graph
matrix[destination][source] = 1;
}
public void printGraph() {
System.out.println("Graph: (Adjacency Matrix)");
for (int i = 0; i < vertex; i++) {
for (int j = 0; j <vertex ; j++) {
System.out.print(matrix[i][j]+ " ");
}
System.out.println();
}
for (int i = 0; i < vertex; i++) {
System.out.print("Vertex " + i + " is connected to:");
for (int j = 0; j <vertex ; j++) {
if(matrix[i][j]==1){
System.out.print(j + " ");
}
}
System.out.println();
}
}
public static void main(String[] args) {
GraphAjdacencyMatrix graph = new GraphAjdacencyMatrix(5);
graph.addEdge(0, 1);
graph.addEdge(0, 4);
graph.addEdge(1, 2);
graph.addEdge(1, 3);
graph.addEdge(1, 4);
graph.addEdge(2, 3);
graph.addEdge(3, 4);
graph.printGraph();
}
}
추가
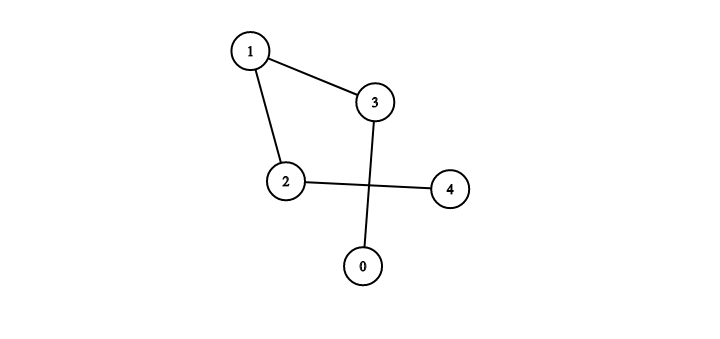 이 그래프는 5개의 노드를 가지고 있고 엣지는 {1, 2}, {1, 3}, {2, 4}, {3, 0} 으로 표현된다.
이 그래프는 5개의 노드를 가지고 있고 엣지는 {1, 2}, {1, 3}, {2, 4}, {3, 0} 으로 표현된다.
정의 하자면 가중치 없는 무방향 그래프를 볼때 인접 행렬의 위치 (i, j)는 노드 i와 j 사이에 간선이 있으면 1이고 그렇지 않으면 0으로 표현된다. 무향 그래프의 경우 인접행렬은 아래처럼 표현된다. (대칭)
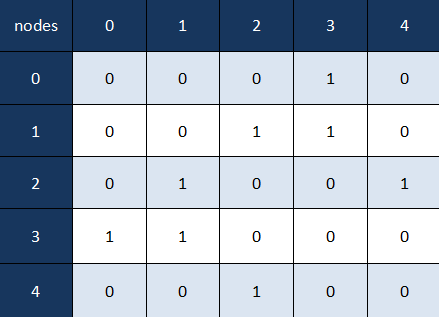
가중 그래프의의 예를 추가로 살펴보자, 노드 (i, j) 사이의 엣지의 가중치(있는경우)를 1대신 표현하고 그렇지 않는 경우 무한대로 표현한다.
왜 무한대를 사용하나?
무한대를 가중치로 사용하는 것은 모서리가 존재하지 않음을 나타내는 "안전한" 방법으로 소개 된다. 그러나 예를들어, 우리가 양의 가중치만 가진다고 가정함녀 -1을 대신 사용하거나우리가 결정한 적절한 값을 사용해도 된다.
마지막 예로 방향 가중치 그래프를 알아보자
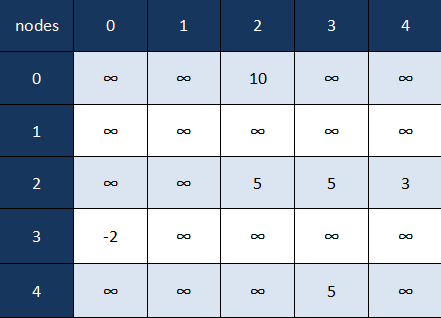
방향 그래프는 보는것처럼 대칭적이지 않다. (0, 3)에는 값이 있지만 (3, 0)에는 값이 존재 하지 안흔다. 또한 완전히 연결되지 않는 노드 또한 가질수 있다.
이젠 위 예제들을 만족하는 예제를 다시 구현해 보자
노드를 정수값 0, 1, …, n-1 로 간단하게 구현해보자
우리는 오늘 구현속에서 가중/비가중 그래프 뿐만아니라 마지막에 살펴본 유향 및 무향 그래프 사이의 선택을 제공하여 그래프를 표현해 볼것이다.
public class Graph {
private int numOfNodes;
private boolean directed;
private boolean weighted;
private float[][] matrix;
// 이러한 방법을 통해 클래스에 가중치 그래프를 안전하게 추가하는것이 가능하다.
// 우리는 의존하지 않고 edge가 존재하는지 확인할 수 있다.
// 특정 특수 값(예: 0)
private boolean[][] isSetMatrix;
public Graph(int numOfNodes, boolean directed, boolean weighted) {
this.directed = directed;
this.weighted = weighted;
this.numOfNodes = numOfNodes;
matrix = new float[numOfNodes][numOfNodes];
isSetMatrix = new boolean[numOfNodes][numOfNodes];
}
public void addEdge(int source, int destination) {
int valueToAdd = 1;
if (weighted) {
valueToAdd = 0;
}
matrix[source][destination] = valueToAdd;
isSetMatrix[source][destination] = true;
if (!directed) {
matrix[destination][source] = valueToAdd;
isSetMatrix[destination][source] = true;
}
}
public void addEdge(int source, int destination, float weight) {
float valueToAdd = weight;
if (!weighted) {
valueToAdd = 1;
}
matrix[source][destination] = valueToAdd;
isSetMatrix[source][destination] = true;
if (!directed) {
matrix[destination][source] = valueToAdd;
isSetMatrix[destination][source] = true;
}
}
public void printMatrix() {
for (int i = 0; i < numOfNodes; i++) {
for (int j = 0; j < numOfNodes; j++) {
// We only want to print the values of those positions that have been marked as set
if (isSetMatrix[i][j])
System.out.format("%8s", String.valueOf(matrix[i][j]));
else System.out.format("%8s", "/ ");
}
System.out.println();
}
}
public void printEdges() {
for (int i = 0; i < numOfNodes; i++) {
System.out.print("Node " + i + " is connected to: ");
for (int j = 0; j < numOfNodes; j++) {
if (isSetMatrix[i][j]) {
System.out.print(j + " ");
}
}
System.out.println();
}
}
public boolean hasEdge(int source, int destination) {
return isSetMatrix[source][destination];
}
public Float getEdgeValue(int source, int destination) {
if (!weighted || !isSetMatrix[source][destination])
return null;
return matrix[source][destination];
}
}
public class GraphShow {
public static void main(String[] args) {
// Graph(numOfNodes, directed, weighted)
Graph graph = new Graph(5, false, true);
graph.addEdge(0, 2, 19);
graph.addEdge(0, 3, -2);
graph.addEdge(1, 2, 3);
graph.addEdge(1, 3); // The default weight is 0 if weighted == true
graph.addEdge(1, 4);
graph.addEdge(2, 3);
graph.addEdge(3, 4);
graph.printMatrix();
System.out.println();
System.out.println();
graph.printEdges();
System.out.println();
System.out.println("Does an edge from 1 to 0 exist?");
if (graph.hasEdge(0,1)) {
System.out.println("Yes");
}
else System.out.println("No");
}
}
5. 그래프 탐색
5-1 DFS 깊이 우선 탐색
깊이 우선탐색에서 단순 트리의 깊이 우선탐색과 그래프의 깊이우선탐색은 조금 다르다. 이걸 알고 두가지가 어떻게 다른지 알아보도록 하자
- 깊이우선탐색 (Depth first search)
- 그래프에서 깊은 부분을 우선적으로 탐색하는 알고리즘
- 보통 스택, 재귀를 활용한다.
- 동작 과정
- 탐색 시작 노드를 스택에 삽입하고 방문처리 한다.
- 스택의 최상단 노드에 방문하지 않은 인접한 노드가 있으면 그 노드를 스택에 넣고 방문 처리를 한다. 방문하지 않는 인접 노드가 없으면 스택에서 최상단 노드를 꺼낸다.
- 2번의 과정을 수행할수 없을 떄까지 반복한다.
DFS 예제
인접 리스트와 행렬을 통해 코드에서 그래프를 표현하는 방법은 위에서 알아보았다, 이제는 그래프를 DFS를 이용하여 그래프를 어떻게 순회하는지 살펴보자.
여기선 인전 리스트 포현을 통한 그래프를 탐색해본다.
public class Node {
int n;
String name;
boolean visited; // New attribute
Node(int n, String name) {
this.n = n;
this.name = name;
visited = false;
}
// Two new methods we'll need in our traversal algorithms
void visit() {
visited = true;
}
void unvisit() {
visited = false;
}
public boolean isVisited() {
return visited;
}
}
package adjacentlist;
import java.util.HashMap;
import java.util.LinkedList;
public class Graph {
// 각 노드맵은 모든 이웃 목록에 매핑이 된다.
// 각 노드맵은 모든 이웃 목록에 매핑이 된다.
private HashMap<Node, LinkedList<Node>> adjacencyMap;
private boolean directed;
public Graph(boolean directed) {
this.directed = directed;
adjacencyMap = new HashMap<>();
}
// add edge 메서드를 추가한다. 이번에는 특별히 helper 메서드를 사용해보도록 하자
// helper 메서드에서 중복 엣지 가능성을 체크한다.
// a와 b사이의 엣지를 추가하기 전에 먼저 기존에 엣지를 확인하고 있으면 기존 엣지를 삭제하고 추가한다.
public void addEdgeHelper(Node a, Node b) {
LinkedList<Node> tmp = adjacencyMap.get(a);
if (tmp != null) {
tmp.remove(b);
}
else tmp = new LinkedList<>();
tmp.add(b);
adjacencyMap.put(a,tmp);
}
public void addEdge(Node source, Node destination) {
// We make sure that every used node shows up in our .keySet()
if (!adjacencyMap.keySet().contains(source))
adjacencyMap.put(source, null);
if (!adjacencyMap.keySet().contains(destination))
adjacencyMap.put(destination, null);
addEdgeHelper(source, destination);
// If a graph is undirected, we want to add an edge from destination to source as well
if (!directed) {
addEdgeHelper(destination, source);
}
}
// 마지막으로 프린트 메서드와 엣지 여부 확인 메서드를 추가하자.
public void printEdges() {
for (Node node : adjacencyMap.keySet()) {
System.out.print("The " + node.name + " has an edge towards: ");
if (adjacencyMap.get(node) != null) {
for (Node neighbor : adjacencyMap.get(node)) {
System.out.print(neighbor.name + " ");
}
System.out.println();
}
else {
System.out.println("none");
}
}
}
public boolean hasEdge(Node source, Node destination) {
return adjacencyMap.containsKey(source) && adjacencyMap.get(source) != null && adjacencyMap.get(source).contains(destination);
}
public void depthFirstSearchModified(Node node) {
depthFirstSearch(node);
for (Node n : adjacencyMap.keySet()) {
if (!n.isVisited()) {
depthFirstSearch(n);
}
}
}
public void depthFirstSearch(Node node) {
node.visit();
System.out.print(node.name + " ");
LinkedList<Node> allNeighbors = adjacencyMap.get(node);
if (allNeighbors == null)
return;
for (Node neighbor : allNeighbors) {
if (!neighbor.isVisited())
depthFirstSearch(neighbor);
}
}
public void resetNodesVisited(){
for(Node node : adjacencyMap.keySet()){
node.unvisit();
}
}
}
여기서 depthFirstSearchModified 메서드는 아래와 같이 서로 완전 독립적인 노드 들을 탐색하기 위해, 사용된 메서드이다.

 DFS 는 가능한 하나의 분기를 통과하기 때문에 “공격적” 그래프 탐색이라고도 한다.
DFS 는 가능한 하나의 분기를 통과하기 때문에 “공격적” 그래프 탐색이라고도 한다.
위 gif를 보면 알수 있듯 DFS는 노드 25를 만나면 더이상 갈 수 없을 때 까지 25-12-6-4 분기를 실행하게 된다. 그런다음 가장 최근에 방문한 노드 부터 다시 시작하여 이전 노드의 방문하지 않은 다른 이웃을 확인 하기 위해 되돌아간다.
참조 https://namu.wiki/w/%EA%B7%B8%EB%9E%98%ED%94%84(%EC%9D%B4%EC%82%B0%EC%88%98%ED%95%99) https://datascienceschool.net/03%20machine%20learning/17.01%20%EA%B7%B8%EB%9E%98%ED%94%84%20%EC%9D%B4%EB%A1%A0%20%EA%B8%B0%EC%B4%88.html https://gmlwjd9405.github.io/2018/08/13/data-structure-graph.html https://kingpodo.tistory.com/46 https://www.youtube.com/watch?v=_hxFgg7TLZQ
Comments